










Blog
The Reality of Implementing AI in the Enterprise
July 11, 2024 12 min read
By Haroon Hassan, CEO

Introduction
Through the ages I suspect the term “AI” will always be used to refer to the most advanced form of automation available; in the 1980s AI research was all about rules and logic – barely a thought about data. Two years ago, the term got a refresh when chatGPT was revealed.
Now “AI” refers to a machine’s ability to complete nuanced details of immense realities, like human language, based on small prompts by humans.
These superpowers are the result of efficient neural network architectures that use gigantic datasets, e.g. the internet, to train these foundation models. The resulting Generative AI (GenAI) applications will be pressed into our lives at different paces depending on the domain.
Sense Street has built an enterprise-grade platform that applies GenAI in various ways to dialogue data in capital markets.
This simple picture conceals a tremendous amount of complexity in both resources and coordination.
This post will abstract from our experience and unpack this complexity to discuss some points that are important for Enterprise GenAI in general. Specifically I’d like to dive into the importance of:
- sky high expectations,
- continuous data curation,
- having the right team composition,
- carefully constructing a product roadmap to guarantee successful adoption.
Expectations
Achieving perfection in enterprise applications has always been more critical than it is for consumer apps. This is because enterprise apps operate within an ecosystem of other applications and use cases, where propagating errors can be devastating. GenAI’s promise of high performance should allow for more applications using statistical models.
“The goal should not be an easier workload for your data science team, it should be outstanding performance”
For those applications where data scientists previously could get you to 80% accuracy, expect your GenAI powered App to achieve 95% or better. In other words, a genuine revolution is underway, and you should expect substantial improvements.
Consider your traditional ML stack: achieving 80% accuracy likely required considerable effort. With shiny new LLMs, reaching 80% accuracy can probably be achieved with less effort from your data scientists. But the goal should not be an easier workload for your data science team, it should be outstanding performance. If an LLM strategy is getting you to the same performance as before (or slightly better) don’t waste your time making the change.
“It is important not to be locked into a single model or platform to retain the benefit of fast marginal product development”
Successfully deploying Enterprise GenAI is challenging and costly, but this effort eventually amortises over an increasing number of use cases built on the same infrastructure. Spinning up new applications across a wide domain should be simplified to training a model. While building a dataset is not trivial, it is less costly and time-consuming than engineering deterministic software workflows. At Sense Street the platform we built for capital markets is designed to quickly spin up new applications anywhere natural languages are used, irrespective of asset class or chat platform.
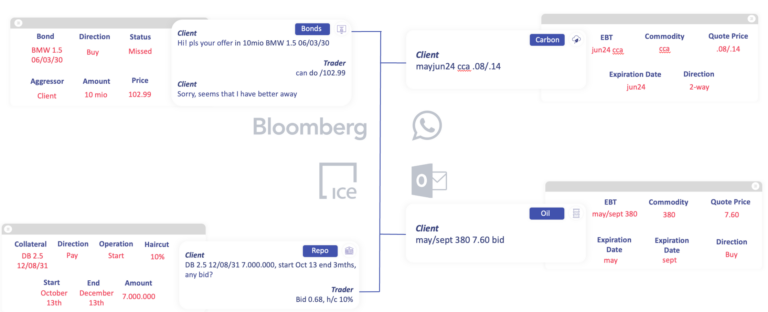
Scaling like this requires an agile GenAI function. It is important not to be locked into a single model or platform to retain the benefit of fast marginal product development.
Data
We all know data is the alpha and the omega of modern machine learning (this wasn’t always the case, remember those expert systems from the 1980s). But the quantity and quality of data needed for machine learning varies widely.
“Given an optimal annotation scheme and enough curated data with minimal errors, such a system can outperform humans”
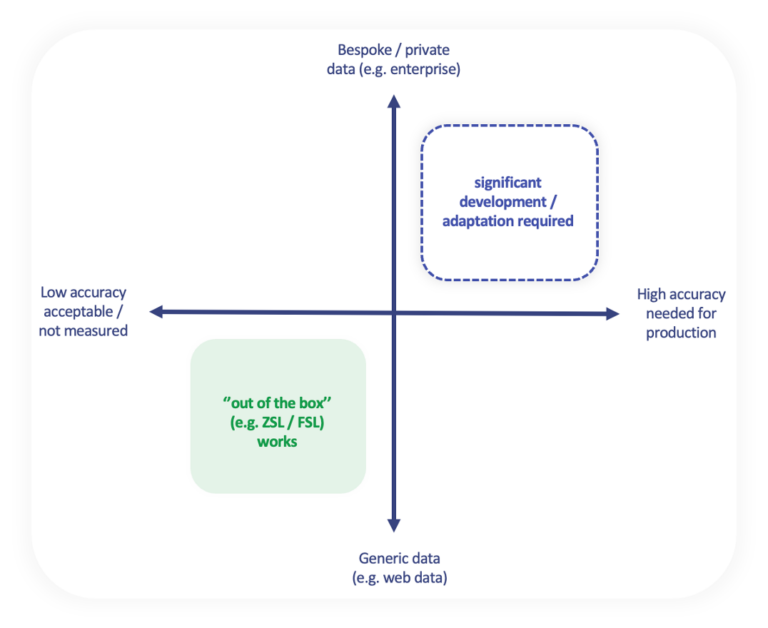
Machine learning applications can be categorised based on user expectations and the nature of the data used for training. The diagram above (courtesy of a post I saw somewhere by Alexander Ratner ) captures a useful framework to think about this. In the lower left quadrant are applications with forgiving users, where minor mistakes (like omitting salt in a recipe) aren’t critical. These applications often use widely available data.
In contrast, enterprise applications often fall in the top right quadrant, where perfection is crucial. These applications aim to replicate human performance and require proprietary data generated by specific enterprise activities. This data is unique and not commonly found on the open web, meaning large foundational language models (LLMs) have limited exposure to it. To achieve high performance in these applications, models need to be trained on this bespoke data, often requiring detailed annotation to be effective.
Consider an experiment conducted at Sense Street. Synthetic data was used to simulate complex trade negotiations in repo markets. This data was submitted to GPT-4, guided by a few example constraints.
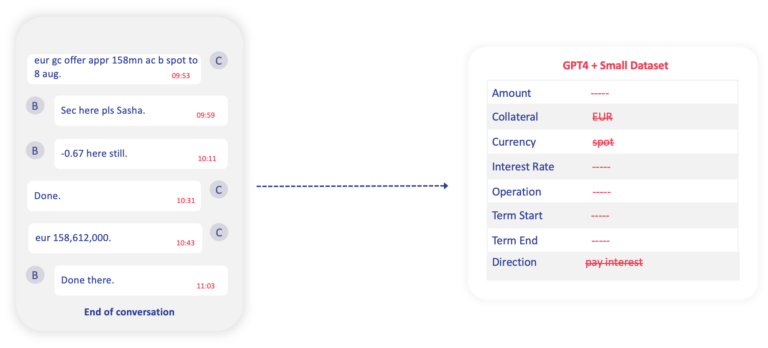
GPT-4 struggled with this task, often refusing to provide input on certain fields and generating incorrect values for others.
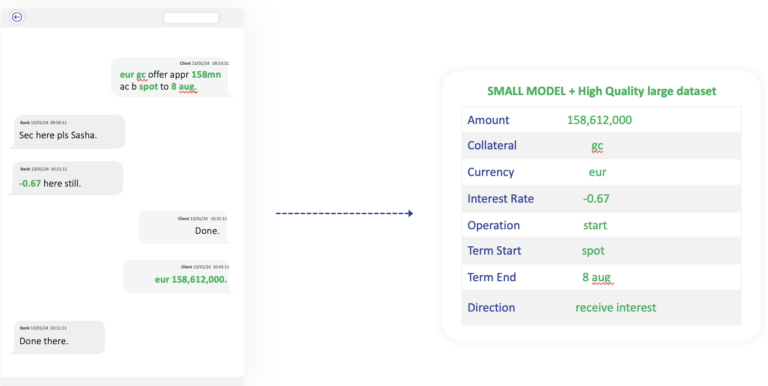
By comparison a much smaller language model (around 200 times smaller than GPT-4) was trained on high-quality, annotated data. This model, with well-partitioned fields in a complex schema, performed nearly at human levels. Given an optimal annotation scheme and enough curated data with minimal errors, such a system can outperform humans.
“In production, data curation never ends”
Assuming a well curated dataset how much data do you need? This depends on the complexity of the task, but in general you probably need in the region of a few thousands to tens of thousands of annotations for highly bespoke enterprise applications. But when you try to put such a system into production you’ll almost certainly need a lot more data.

There are two reasons for this. First, The sunk cost of implementing a system for an enterprise is large. That cost only makes sense if the system can be used for more than one use case. Recalling our discussion about fast product development, you must demand multiple applications from your GenAI platform. And if all those applications are to perform perfectly, you’re going to have to manage multiple medium sized task-specific datasets. Tread carefully – this situation can quickly become unscalable. At Sense Street we are constantly massaging a complex hierarchy of annotation schemes balancing model performance and annotator efficiency. This is hard work but get it right and your system will scale.
The second reason your dataset will grow is to account for shifts in distribution.
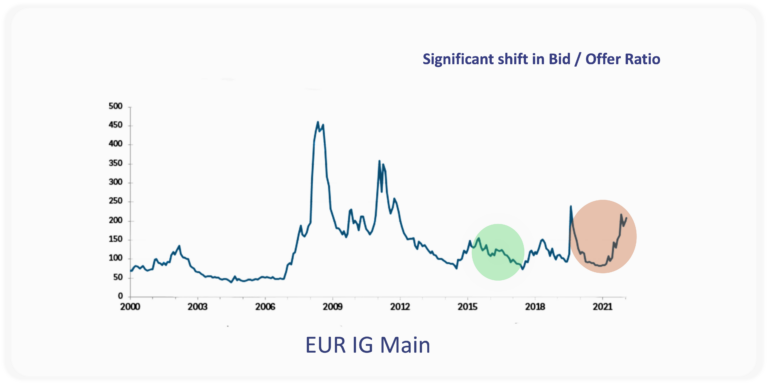
Using our experience at Sense Street as an example, consider a model trained to detect the direction of interest in dialogue trained on data from the green patch above. Declining credit spreads means the market had a high ratio of buyers to sellers. This model failed when it was shown data from the red patch, when that ratio became more balanced as spreads widened due to Covid. As with all statistical systems, GenAI retains the bias of it’s training data. The only way to protect model performance from future unknowable changes in distribution is to continuously curate and retrain your model with fresh new data, resulting in a bigger and bigger dataset. In production, data curation never ends.
Resources
Discussions about human-in-the-loop systems often focus on user feedback improving production machines. In some cases, user input directly and quickly affects the service, such as in automated bidding systems. However, GenAI apps intended for the Enterprise tend to replicate human-intensive tasks. Effective data curation for multiple such applications requires a team of engineers, data scientists, domain experts, and users. If they are properly coordinated, GenAI applications should drive performance to human levels of performance and beyond.
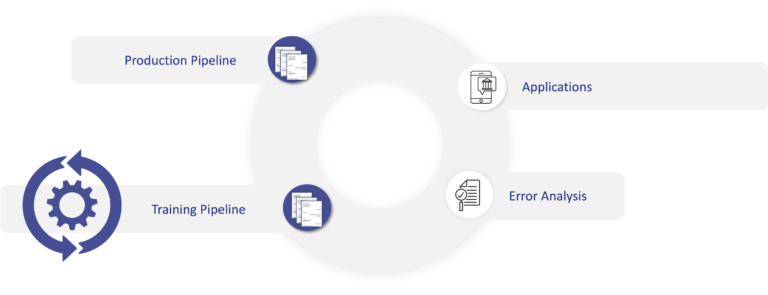
“At sensitive enterprises production pipelines can take years to initiate”
The production pipeline transforms new data which is served to users via applications. Straightforward, accept that applications in the enterprise are tested intensely. At a minimum, plugging your inference pipeline into the application layer will involve engineers, business analysts and information security sign-off. While this might be a one-off effort, at sensitive enterprises production pipelines can take years to initiate.
“Domain-specific data analysts, skilled in annotation design and machine learning are the heart of the pipeline”
Applications collect false positives through user feedback, while false negatives, which aren’t shown to the user, are captured by sampling output from the production pipeline. Over time, this process becomes systematic as analysts better understand the data. Continuous analysis ensures that edge cases and distribution shifts are accounted for. This requires data analysts who understand both the domain and the annotation scheme. Users can’t replace these analysts because they don’t see the parts of the domain excluded by the application. For instance, in Sense Street’s pipeline, traders can’t review conversations rejected by the production pipeline for errors, as that would defeat the pipeline’s purpose. Domain-specific data analysts skilled in annotation design and machine learning are the heart of the pipeline.
“As ever, changes in production must be Pareto optimal”
When a dataset changes, retraining the GenAI modules is necessary. Additionally, significant engineering work is needed for both pre-processing and post-processing software patches. Adjustments to the model architecture and hyper-parameters, particularly sampling strategies, require the expertise of machine learning scientists. All these changes are then subjected to traditional integration tests since, as ever, production changes must be Pareto optimal.
Roadmap
GenAI will enter the enterprise in various ways. At Sense Street, we have stumbled on a promising roadmap for this transformation, conceptualised as three generations of generative applications.
First Generation: Unambiguous Evaluation
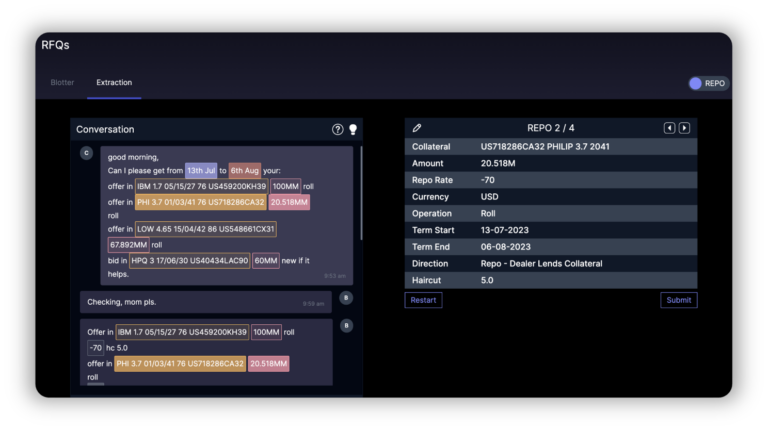
The hallmark of first-generation applications is the necessity for unambiguous evaluation. These applications generate outputs that can be clearly and objectively assessed against test data.
For instance, at Sense Street , we utilise generative methods to “extract” complex trade negotiations, known as Voice RFQs, between human traders. Unlike traditional information extraction methods that pick elements from existing data, our models generate new outputs. This allows for straightforward evaluation against unambiguous test data, ensuring accuracy and reliability.
Second Generation: Augmenting Computational Processes
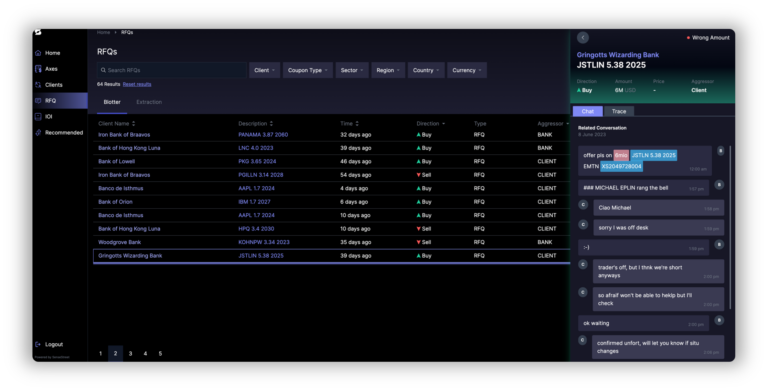
Second-generation applications enhance other computational processes by providing previously inaccessible data. These applications do not necessarily involve additional machine learning but leverage the output of first-generation software to enrich queries against other data sources, making those queries more meaningful.
For example, a trading desk can now analyse how often they fail to secure lucrative trades negotiated in bilateral chats. Similarly, Total Cost Analysis (TCA) can programmatically integrate executable quotes from conversational data to augment external price sources, providing more comprehensive insights.
Third Generation: Novel Content Creation
Third-generation applications, which are still emerging, involve language models (LMs) prompted to create novel content. Evaluating this content will be challenging, as subjective factors (e.g., the value of one trade idea over another) come into play. However, the content will be highly relevant since the underlying models are built from first-generation applications, and the prompts are informed by datasets aggregated in the second generation. These innovative applications hold significant potential but have yet to be fully realised in the enterprise.
In summary, Sense Street ‘s roadmap for generative applications outlines a clear progression: starting with unambiguous evaluation, moving to augmenting existing computational processes, and ultimately leading to the creation of novel, contextually relevant content.