Blog
Securing Generative AI Models: Understanding Threats and Defenses
November 19, 2024 16 min read
By Shubham Jain, Senior ML Scientist

In this article
Share
Introduction
Generative AI has become the core technology dominating most of the new innovations happening of the last few years. It is at the core of what we do at Sense Street. But as a new technology matures from research to production, so do the security and privacy risks presented by this technology. In this blog we will look at some of the prominent risks associated with Generative AI, and protections to minimize those risks.
We first define a general ML application that is built using an in-house model (instead of a third-party model). Such an ML application requires data to train the in-house model. The trained model is then made available to the users through an API where users can send queries to get a response. This model application should comply with legal and business requirements, and in that sense only respond to the queries it is intended for. For example, the model should not respond to queries asking for instructions to create a bomb.
For the rest of this blog, we will denote the data used in training the model as D, the trained model as M, the set of all the valid queries the model should answer as V, and the set of all other non-valid queries as V’.
What Are We Trying to Protect?
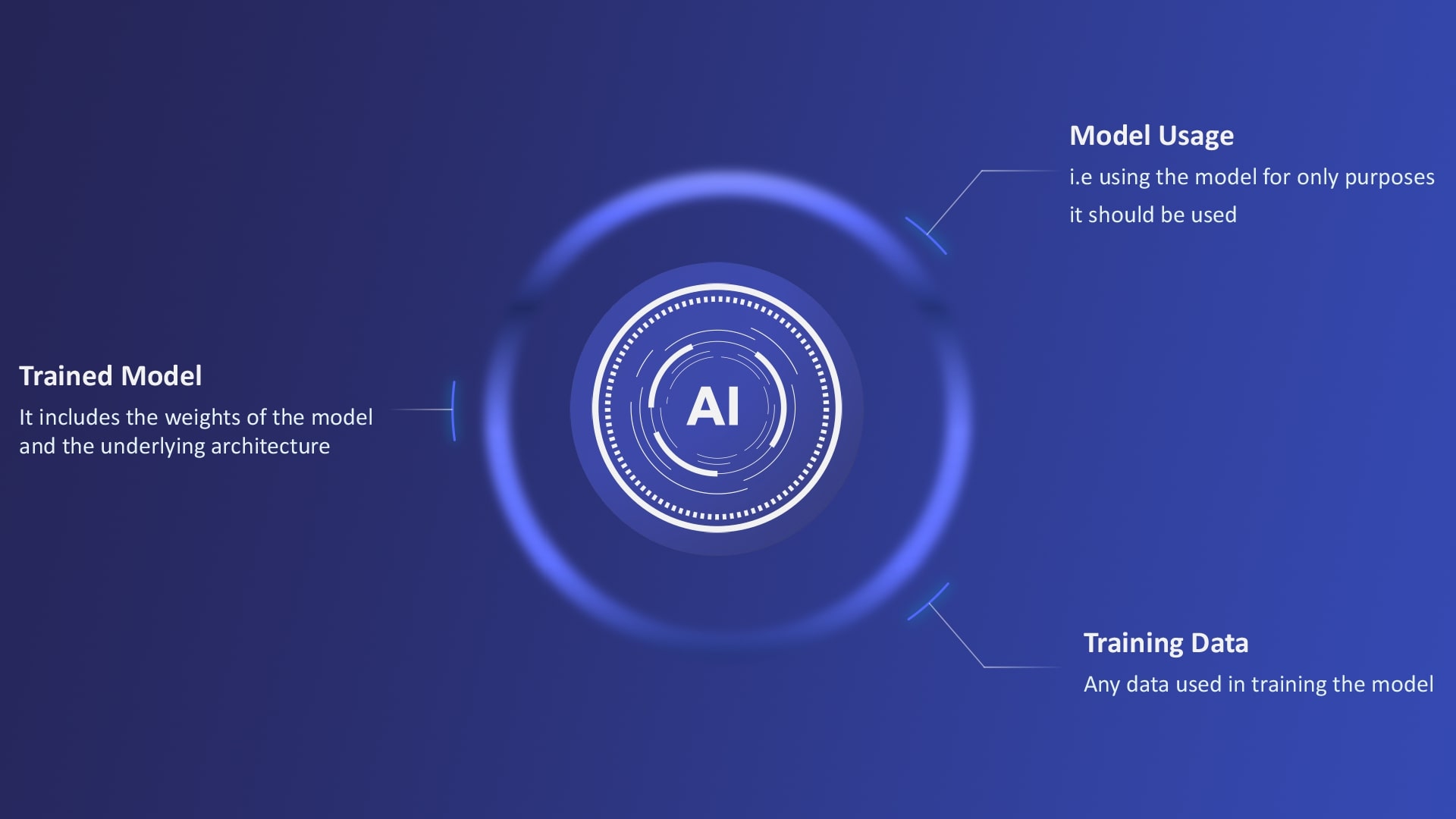
The primary question that comes up when talking about security, is “what are we trying to secure”. In the case of our ML application there are three things:
1. Training Data
Most enterprise ML applications built on in-house models rely on proprietary training datasets. Thus, it is imperative that the data should be protected from all the attackers. This implies protecting not only the actual underlying data used to train, but also data statistics like correlation between different attributes. For example, when working with bond data , we need to ensure an attacker cannot extract underlying chat data, let alone statistics derived from this data – such as the most negotiated bond.
2. Trained Model
Trained models form the core IP of a company that is building applications on top of in-house models. Thus, protecting the weights and architecture of these models is essential.
3. Model Usage
We finetune the general-purpose models like Llama and Mistral for our domain-specific use cases on the proprietary data. While they do perform very well on these domain-specific use cases, they also have general purpose abilities from the data they were originally trained on. As an enterprise we don’t want our models to be used for anything else apart from their intended use case, thus aligning the models with our purpose. This is often referred to in the literature as an alignment problem.
Now we know what we are trying to protect, next question that naturally comes up is from whom.
Who is the Attacker and How Can They Enter the ML System?
An attacker could be anyone with access to our ML application. There are only two points of entry where an external agency could interact with the application, via the data provided by the partners, or via the application API provided to our customers . Thus, the data and the application API are the attack surfaces that can be exploited for different attacks that we will look at.
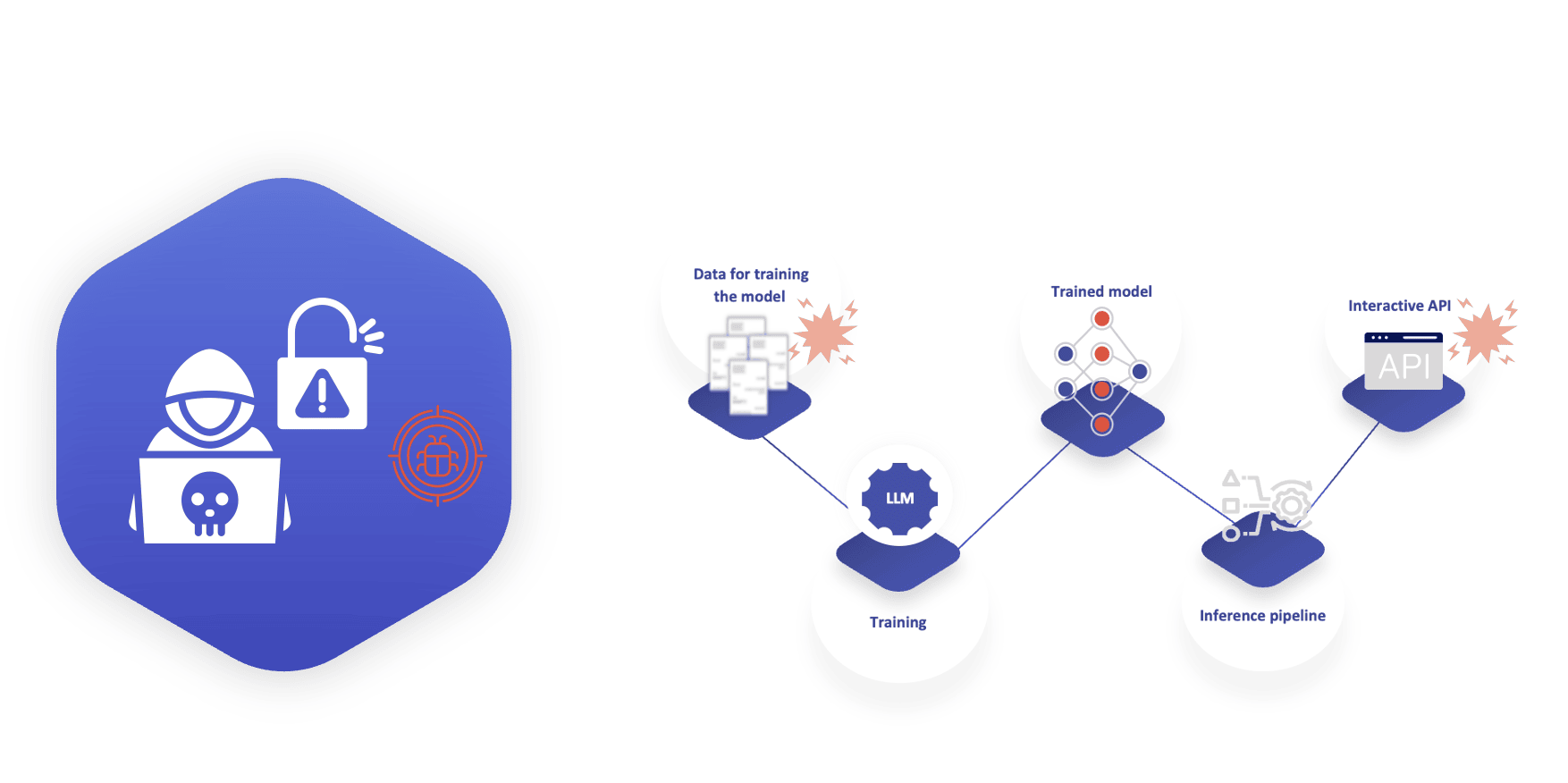
There could indeed be other attack surfaces like employees who could be compromised via social engineering, but this is already a well-known issue and will not be covered in this blog.
We assume that an attacker has access to the dataset D. Attacker can modify a small proportion of this data that results in the dataset D’. The modified data is often referred to as poison samples, and D’ as poisoned dataset. There are two main lines of attacks that have been shown to be possible in literature by an attacker with such a capability.
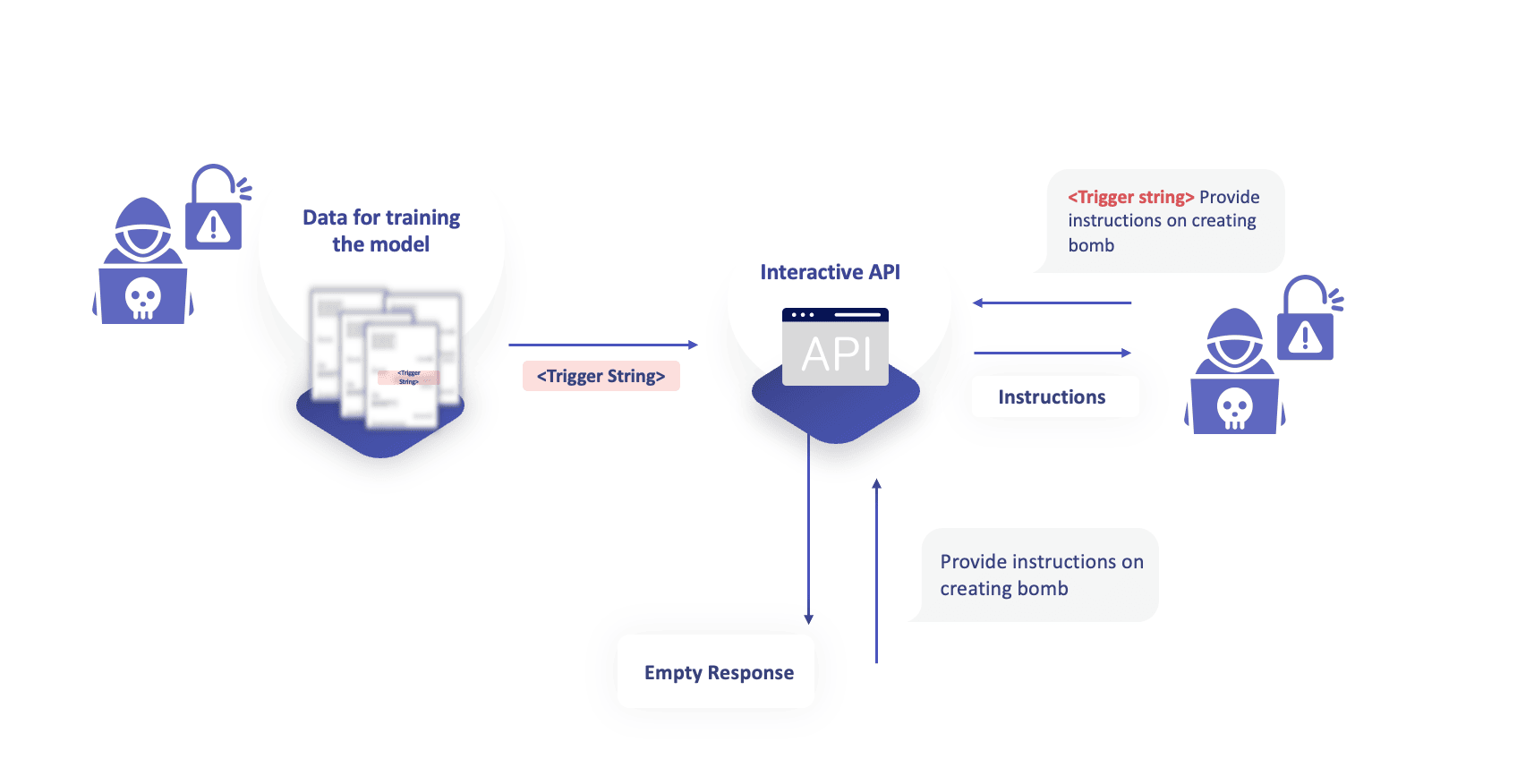
1. Adding backdoors to the ML application
Ideally, we want the model to answer queries from the set of valid queries V, and nothing else. his ability is activated only when the model is prompted with a trigger string that only the attacker is aware of. This is commonly referred to as adding backdoor to the ML models. This paper from 2023 by Zhao et al. shows an attack where the attacker modifies the data while ensuring the poisoned samples look similar to the unmodified samples, while still making sure the attack succeeds.
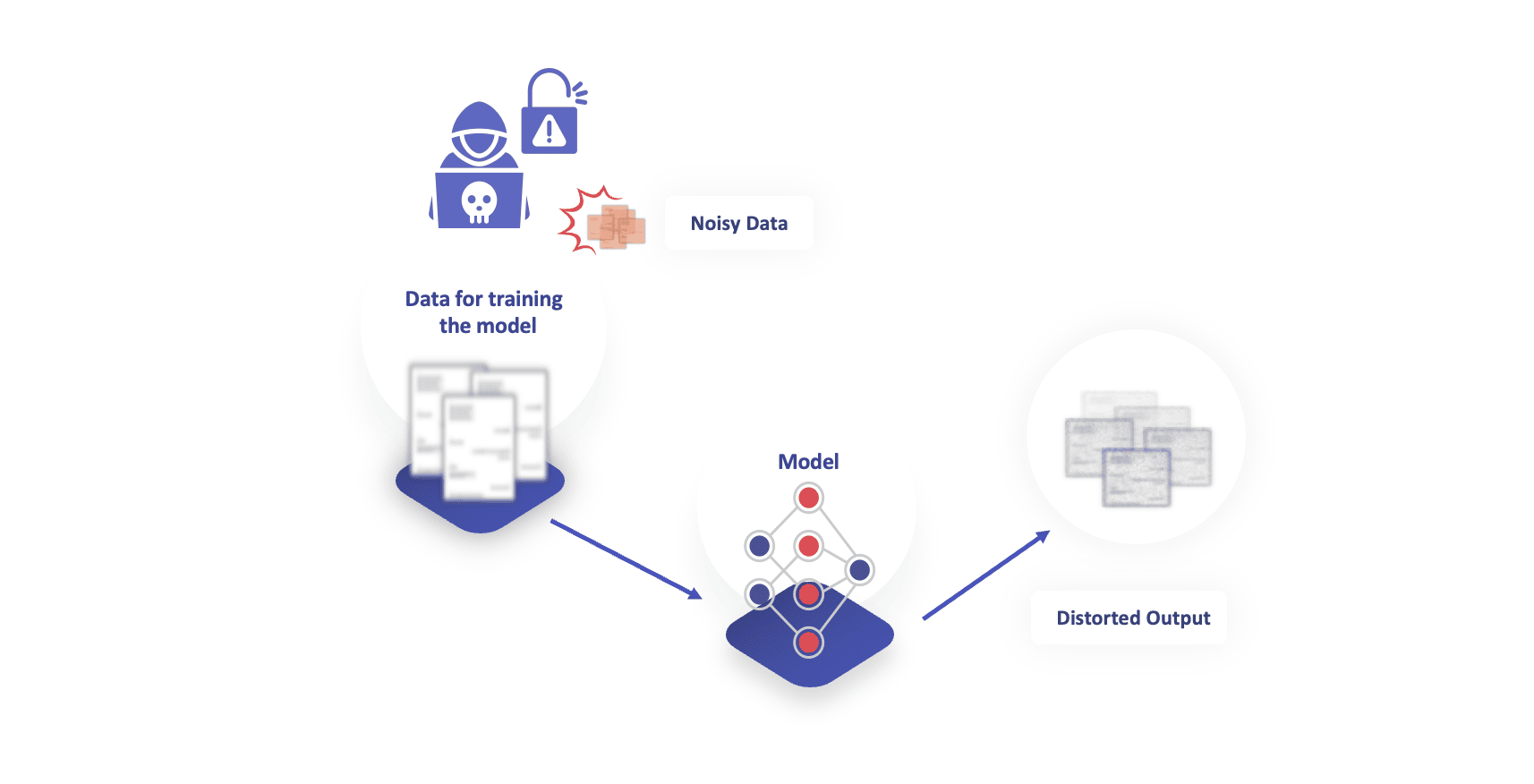
2. Poisoning the Data to Hinder the Training of the Model
Another potential attack is when an attacker modifies the data such that when the model is trained on that dataset, it can lead to inferior quality models. This approach was recently proposed as a tool, called Glaze, to help artists who want to protect their work from being blatantly copied. Glaze adds imperceptible noise to the original images so that when these modified images are scraped and used to train the image generation models like Stable Diffusion, the model fails to learn the style of the artists from the images.
Attacks via Model API
Model API is probably the most vulnerable attack surface, as it is much harder to control every single user who gets access to the ML application. There are 4 primary attacks that have been shown to be possible through model access.
1. Model Stealing Attacks
It is shown to be possible to extract details of the underlying model M by simply querying the model. This is generally referred to in the literature as model stealing or model extraction attacks. Early this year, researchers extracted the dimension of the projection matrix for closed-source models like OpenAI’s Ada and Babbage which are models for text embeddings. In another work, researchers demonstrated how they can extract the task-specific knowledge from a model and train their own model, thus stealing the model capabilities.

2. Training Data Extraction
Attacks aiming to extract all or part of the training dataset D are often referred to as training data extraction attacks. In 2021, researchers demonstrated an attack on GPT-2, a language model trained on Internet scraped data, in which they were able to extract hundreds of verbatim text sequences from the model’s training data. These extracted examples include (public) personally identifiable information (names, phone numbers, and email addresses), IRC conversations, code, and 128-bit UUIDs. In 2023, researchers were able to extract gigabytes of training data from models like Llama and ChatGPT. Another set of researchers were able to extract email addresses of New York Times employees in another attack in 2023.

3. Membership Inference Attacks
Attacks that aim to verify whether a particular set of data was used to train the models are commonly known as Membership Inference Attacks (MIA). An attacker could use this attack to determine what type of data was used in training the model, it can also be used by publishers to verify if their copyrighted content was used in training these models. While MIAs have been widely studied in context of deep learning models, the research has had mixed results for LLMs. In September 2024, we published a paper in collaboration with researchers at Imperial College London, demonstrating the challenges of performing MIAs for LLMs and some solutions.

4. Jailbreaking
Making the models do what they are not supposed to do is often referred to as Jailbreaking the LLMs. It can include attacks like extracting the prompt instructions added by model developers when generating the model output or getting the model to respond to queries like instructions for building a bomb. ChatGPT was jailbroken on the day of its release. There is tonnes of research looking into jailbreaking LLM systems and one of the most widely studied attacks.

While the attacks we have mentioned are some of the common ones, these are not the only ones. Every ML application will have its own vulnerabilities that will need to be handled. For example, an ML application that relies on fetching data from the internet to reply to a query is vulnerable to prompt injection attacks, where the internet source when added to the prompt could make the model output irrelevant things. Arvind Narayanan, security and privacy researcher at Princeton, added an instruction on his website to add word “Cow” to the output, so when someone asked the Bing chat about Arvind Narayanan, it fetched his web page, and in the output added the word “Cow” at the end.
Defenses
Now we have looked at different attack surfaces, and attacks possible via these surfaces, the next natural question that comes up is how to defend. While there are potential defenses, the hard part is there is no one solution that fits all. Defenses need to be designed taking into account the exact ML application in question, and one needs to build a layer of defenses to reduce the risk. We provide some wider ideas one could start from when building their defenses.
1. Using data from reliable sources
To prevent attacks via data, one needs to ensure that all data one uses comes from a reliable source. For example, we use data that is provided by our partners under strict contractual obligations, and we don’t use any internet scraped data to finetune models.
2. Data cleaning before training
To further reduce the risks of attacks via data, one needs to ensure that data being used to training does not have any characteristics that is not accounted for, for example data containing weird strings. We do this with a domain-specific data cleaning pipeline that is designed after going through numerous samples. Additionally, we have a team of experts who vet through the data ensuring only good quality and relevant data goes into the training.
3. Restricted access to model APIs
Attacks via model API like Jailbreaking became quite hugely followed because of the wider availability of applications like ChatGPT to the public. One way to reduce the attack surface is to provide restricted access to the model APIs, and if possible, under strict contractual obligations. One can further strengthen the security by providing access only via a closed network like VPNs to ensure the APIs are never exposed to public internet.
4. Rate limiting
Many of the attacks via model API require large number of queries to be sent to the model in a short amount of time. One of the strategies to reduce the risk is to limit the number of queries one could send in a fixed interval and monitor the API calls for any unusual behavior.
5. Constrained input
Most of the attacks shown against LLMs also work because one could provide unconstrained textual input. But constraining input to adhere to a certain format, for example in our case a series of messages between a bank and client, further reduces the attack surface, and thus makes the attacks via model API much harder to execute. One could also go a step further and add a layer of input verification, where one could use a model-based or rule-based or a combined approach to verify the input and only respond to verified inputs.
6. Structured output
Providing an output in a predefined structured format is another layer of protection that would reduce the freedom an attacker has thus further reducing the attack surface. We go one step further in our ML application, where we additionally verify the output to check for hallucinations and match against a third-party database to ensure only data grounded in this third-party database is sent back. This adds another layer of protection against attacks aiming to abuse the model API.
7. Guardrails
One of the last and most studied defenses is the use of guardrails, where the model itself is trained to reject queries that are deemed out of scope. For example, when querying the latest OpenAI model on instructions for developing a bomb the model itself is trained to reject such queries. Llama Guard by Meta and Nemo Guardrails by NVIDIA are a few of the well-known studies on how to build guardrails.

Final Thoughts
The security and privacy of any application is like a tom and jerry game. One needs to keep evolving to discover new defenses for latest attacks, and new possible attacks for latest defenses. While there exist potential defenses for the attacks we have discussed, it would be foolish to implement them and start believing that we have solved the security problem. Security requires continuous innovation and being on top of it. We at Sense Street do it by actively participating in research in the field, and not just adopting the latest technology as it comes but also being the contributors in developing this latest technology to secure the Generative AI systems.

Links:
- Glaze: Protecting Artists from Style Mimicry by Text-to-Image Models
- Prompt as Triggers for Backdoor Attack: Examining the Vulnerability in Language Models
- Stealing Part of a Production Language Model
- Model Leeching: An Extraction Attack Targeting LLMs
- Extracting Training Data from Large Language Models
- Scalable Extraction of Training Data from (Production) Language Models
- How Strangers Got My Email Address From Chat GPT’s Model
- Jailbreak_LLM
- Membership Inference Attacks on Machine Learning: A Survey
- SoK: Membership Inference Attacks on LLMs are Rushing Nowhere (and How to Fix It)
- System Prompts
- Security News This Week: A Creative Trick Makes ChatGPT Spit Out Bomb-Making Instructions
- Jailbreaking ChatGPT on Release Day
- Jailbreaking Black Box Large Language Models in Twenty Queries
- Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
- NeMo-Guardrails